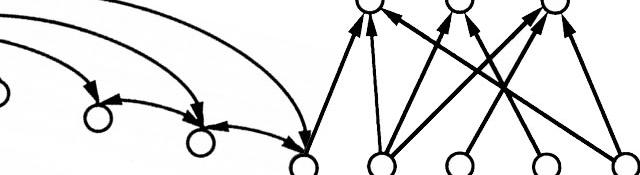
7 unique neural network architectures
They way you interconnect neurons plays an extremely important role. In fact, researchers try to find new architectures that can be used for many purposes. I'll talk about a few architectures over here.
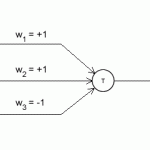
The dictomizer
You've already seen this one. It consists of a single neuron, and can classify between two different sets. Nothing fancy here. Just one single neuron does the job. The "learning" is simple to implement. There are no "feedback" connections (it's output is not recycled).
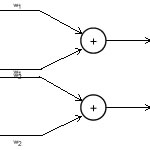
Multicategory Classifier
Suppose you have more than two classes. Like "human", "animal" or "neither of the above". Then you use multiple neurons (corresponding to each separating line). Again, the input is not recycled. The learning in this case is simple too. And it is quite similar to the previous case.
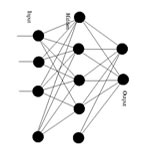
Multilayer feedforward networks
Here, several neurons are arranged in "layers". The output of one layer is the input for the next one. Learning for these networks is not as obvious as the previous networks. In fact, training these networks became possible only two decades back using the back-propagation algorithm!
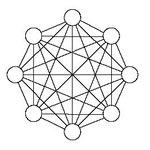
Hopfield networks
This network is an example of a single layer-feedback network. That is, the output of a neuron is recycled as the input for other neurons. This has many applications, as we will see later on. This is a "single layer" of neurons. For two layered Hopfield networks, things become way too complex.
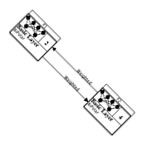
Associative memories
These are similar to the hopfield network, except that they mimic human memories. You "remind" it of a partial memory, and it'll give you the complete memory.
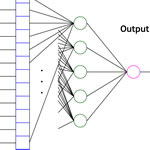
Hamming & MAXNET
These networks help in classification (just like the dictomizer/multicategory classifier), but using another technique. We'll go into the details of this network pretty late. This network can be used in unsupervised learning as well.
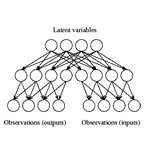
Unsupervised learning
All previous networks require supervised learning. That is, you give the network an input, and the expected output. The network then adapts accordingly. In this network, no expected output is required. The network "learns" on itself. As impossible as it may sound, it is possible :)
We'll go through each of the above networks in detail. Also working through some math to figure things out. And even working on how to implement these networks in code.
Related posts



